In Standalone and Mesos modes, this file can give machine specific information such as hostnames.
set SPARK_HOME=%~dp0 .. rem Only attempt to find SPARK_HOME if it is not set. For example, D:\spark\spark-2.2.1-bin-hadoop2.7\bin\winutils.exe. The user can specify multiple of these to set multiple environment variables. Next, well want to install VSCode in Windows. In Start Menu type Environment Variables and select Setup new environment variable SPARK_HOME Search for Environment Variables on Windows search bar; Click on Add Environment Variables; There will be 2 categories of environment variables User Variables on top; System Variables on bottom; Make sure to click on Add for System Variables; Name: SPARK_HOME; Value: C:\spark-2.3.0-bin-hadoop2.7 (dont include Note: A new instance of the command-line may be required if any environment variables were updated.. Building.
PySpark : So if you correctly reached this point , that means your Spark environment is Ready in Windows. But for pyspark , you will also need to install Python choose python 3. The function is mostly invoked for the side-effect of setting the SPARK_HOME environment variable. In order to run PySpark (Spark with Python) you would need to have Java installed on your Mac, Linux or Windows, without Java installation & not having JAVA_HOME environment variable set with Java installation path or not having PYSPARK_SUBMIT_ARGS, you would get Exception: Then you will see this dialog: 3.Create the JAVA_HOME environment variable by clicking the New button at the bottom. You can print your new environment variable with printenv and see how your date was set on Linux by modifying TZ. spark-shell. set PATH=%SPARK_HOME%\bin;%PATH% Verify you are able to run spark-shell from your Based on what I have chosen , I will need to add the following variables as Environment variables SPARK_HOME C:\Spark\spark-2.2.1-bin-hadoop2.7 HADOOP_HOME C:\Hadoop JAVA_HOME C:\Program Files\Java\jdk1.8.0_191 These values are as per my folder structure. 1.
For example to set the JAVA_HOME variable, you would use: SETX JAVA_HOME "C:\Program Files\Java\jdk1.6.0_02". Use Apache Spark with Python on Windows. Examples ## Not run: # Not run due to side-effects spark_home_set() ## End(Not run) Introduction. This documentation is for Spark version 3.1.1. First run the command hadoop classpath from the commandline inside %HADOOP_HOME% and copy the output. master ("local [1]"). SCALA_HOME = bin. To do so, run the following command in this format: start-slave.sh spark://master:port. To install on Windows, grab Go and select Windows as your platform. Python | os.environ object.
2) Setup SPARK_HOME variable.
You can find the environment variable settings by putting environ in the search box. Before starting Zeppelin, make sure JAVA_HOME environment variable is set.
Property spark.pyspark.driver.python take precedence if it is set. Setting User Environment Variable.
d) Create another system environment variable in Windows called HADOOP_HOME that points to the hadoop folder inside the SPARK_HOME folder. Solution: Pyspark: Exception: Java gateway process exited before sending the driver its port number . Right-click your Windows menu, select Control Panel, System and Security, and then System. Exception: Python in worker has different version 2.7 than that in driver 3.5, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set. Testing Apache Spark on Windows. Next, launch Python or IPython and use the following code. 6. Before starting PySpark, you need to set the following environments to set the Spark path and the Py4j path. rem need to search the different Python directories for a Spark installation. Otherwise, just use the export command (or set command in Windows) to set your environment variables.
After that, uncompress the tar file into the directory where you want to install Spark, for example, as below: tar xzvf spark-3.3.0-bin-hadoop3.tgz. set SPARK_HOME=%~dp0 .. rem Only attempt to find SPARK_HOME if it is not set. def configure_spark (spark_home=None, pyspark_python=None): spark_home = spark_home or "/path/to/default/spark/home" os.environ ['SPARK_HOME'] = spark_home # Add the PySpark directories to the Python path: sys.path.insert (1, os.path.join (spark_home,
Open Eclipse and do File => New Project => Select Maven Project; see below. For this tutorial we'll be using Scala, but Spark also supports development with Java, and Python.We will be using be using IntelliJ Version: 2018.2 as our IDE running on Mac OSx High Sierra, and since we're using Scala we'll use SBT as our build Step 2: Open the downloaded Java SE Development Kit and follow along with the instructions for installation. rem need to search the different Python directories for a Spark installation. Set the output of the command run in Step 1 to the value of environment variable SPARK_DIST_CLASSPATH. OS module in Python provides functions for interacting with the operating system. You can override the Spark configuration by setting the SPARK_CONF_DIR environment variable before starting Livy. Set JAVA_HOME to C:\Program Files\Java\jdk1.8.0_201 (removing the bin) Set HADOOP_HOME to the parent directory of where you saved winutils.exe (and not spark as you are doing currently). To do so, Go to the Java download page. 2. For example, *C:\bin\spark-3.0.1-bin-hadoop2.7*. spark-path-set-up. Setup new environment variable SPARK_HOME Search for Environment Variables on Windows search bar; Click on Add Environment Variables; There will be 2 categories of environment variables User Variables on top; System Variables on bottom; Make sure to click on Add for System Variables; Name: SPARK_HOME; Value: C:\spark-1.6.3-bin-hadoop2.7 (dont include Configurations can be found on the pages for each mode: Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows). If you need to add a library, use the environment variable below. Run below commands in sequence. Installing Java: Step 1: Download the Java JDK. For the rest of the section, it is assumed that you have cloned
It means you need to install Java. You have now set up spark! Edit your BASH profile to add Spark to your PATH and to set the SPARK_HOME environment variable. Testing the Jupyter Notebook. init () import pyspark from pyspark. Now add External Jars from the location D: \ spark \ spark-2.0.1-bin-hadoop2.7 \ lib; see below. Prerequisites. Install Spark (Setup environment variables) Now please set environment variable, By running below command in command prompt. Now that a worker is up and running, if you reload Spark Masters Web UI, you should see it on the list: In case the download link has changed, search for Java SE Runtime Environment on the internet and you should be able to find the download page.. Click the Download button beneath JRE. For Linux machines, you can specify it through ~/.bashrc. By default, Spark SQL does not run on some OS and For both our training as well as analysis and development in SigDelta, we often use Apache Sparks Python API, aka PySpark. The System Properties dialog appears, click the button Environment Variables. 5. Add the following environment variable. 4. Set the environment variables: SPARK_HOME = D:\Spark\spark-2.3.0-bin I've documented here, step-by-step, how I
Despite the fact, that Python is present in Apache Spark from almost the beginning of the project (version 0.7.0 to be exact), the installation was not exactly the pip-install type of setup Python community is Run the following command in Command Prompt (Remember to the path to your own Zeppelin folder): cd /D F:\DataAnalytics\zeppelin-0.7.3-bin-all\bin Then, select the Edit button to configure the PATH system variable. You need to do this if you wish to persist the SPARK_HOME variable beyond the current session. And Create New or Edit if already available.
OS comes under Pythons standard utility modules. spark-user-path-variable.
To test that spark is set up correctly, open the command prompt and cd into the spark folder: C:Sparkspark-2.3.2-bin-hadoop2.7bin. Open the Environment variables windows . The variables to add are, in my example, Ensure the SPARK_HOME environment variable points to the directory where the tar file has been extracted. Press Windows + R to open the Windows Run prompt. The SPARK_HOME environment variable could also be set using the .bashrc file or similar user or system profile scripts. It is strongly recommended to configure Spark to submit applications in YARN cluster mode.
Installing and Running Hadoop and Spark on Windows We recently got a big new server at work to run Hadoop and Spark (H/S) on for a proof-of-concept test of some software we're writing for the biopharmaceutical industry and I hit a few snags while trying to get H/S up and running on Windows Server 2016 / Windows 10. In addition, it integrates smoothly with HIVE and HDFS and provides a seamless experience of parallel data processing. I typically use a function like the following to make things a bit less repetitive. It can change or be removed between minor releases. This is a very easy tutorial that will let you install Spark in your Windows PC without using Docker. @idjaw nice linkLINL SOLVED: py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getEncryptionEnabled does not exist in the JVM. For example, C:\bin\spark-3.0.1-bin-hadoop2.7\bin. Since we have configured the integration by now, the only thing left is to test if all is working fine. JAVA_HOME environment variable value should be your Java JRE path. Add the environment variable specified by EnvironmentVariableName to the Executor process. This tutorial will teach you how to set up a full development environment for developing and debugging Spark applications.
6) Configure Apache Toree installation with Jupyter: Within the Environment Variables window, select the Path variable from the User variables for
Add a new environment variable SPARK_HOME. Set JAVA_HOME Variables: To set the JAVA_HOME variable follow the below steps: Click on the User variable Open the Start menu and type edit ENV into the search bar. Setup SPARK_HOME environment variable with value of your spark installation directory.
Spark 3.0 files are now extracted to F:\big-data\spark-3.0.0. To add a HADOOP_HOME, open the Environment variables dialogue box and click on the New button in the System variable section and fill the Name and Value text boxes, as shown in the image below: Open your downloaded Spark gz file using 7-zip (i.e. spark-2.4.4-bin-hadoop2.7.gz). Start Zeppelin. Feel there is a better way? Type in sysdm.cpl and click OK. 3. In this article. Step 7: Configure Environment Variables 1. Run the windows installer downloaded and accept the defaults. If you already have all of the following prerequisites, skip to the build steps.. Download and install the .NET Core SDK - installing the SDK will add the dotnet toolchain to your path. Run one of the following commands to set the DOTNET_WORKER_DIR environment variable, which is used by .NET apps to locate .NET for Apache Spark worker binaries.
Select the result labeled Edit the system environment variables. import findspark findspark. (Depending upon the version of the JDK installed, bitness of your OS, change the JDK folder path accordingly.) In the lower-right corner, click Environment Variables and then click New in 4. Linux, Mac OS). I have the following variables in .bashrc. Edit pom.xml. Setup environment variable JAVA_HOME if it is not done yet. In our case it is ubuntu1: start-slave.sh spark://ubuntu1:7077. Follow the steps to set environment variables using the Windows GUI: 1. Spark is the most popular, fast and reliable cluster computing technology. In Standalone and Mesos modes, this file can give machine specific information such as hostnames. If SPARK_HOME is set to a version of Spark other than the one in the client, you should unset the SPARK_HOME variable and try again. to know the command usage.
$ printenv TZ America/New_York $ date Sat 19 Oct 2019 10:03:00 AM EDT Spark uses Hadoops client libraries for HDFS and YARN. 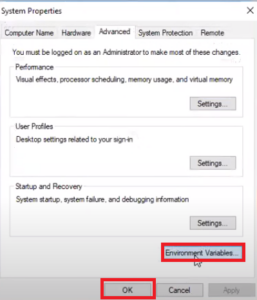 How To Install Apache Spark On Windows 10: Step 1: Download winutils.exe Windows 10 operating system from git hub below link: After downloading the Wintulins file and create your own convenient. Environment Variables. Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows). In Standalone and Mesos modes, this file can give machine specific information such as hostnames. This tutorial will demonstrate the installation of PySpark and hot to manage the environment variables in Windows, Linux, and Mac Operating System. This article teaches you how to build your .NET for Apache Spark applications on Windows. How To Install Apache Spark On Windows 10: Step 1: Download winutils.exe Windows 10 operating system from git hub below link: After downloading the Wintulins file and create your own convenient. 7.
How To Install Apache Spark On Windows 10: Step 1: Download winutils.exe Windows 10 operating system from git hub below link: After downloading the Wintulins file and create your own convenient. Environment Variables. Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows). In Standalone and Mesos modes, this file can give machine specific information such as hostnames. This tutorial will demonstrate the installation of PySpark and hot to manage the environment variables in Windows, Linux, and Mac Operating System. This article teaches you how to build your .NET for Apache Spark applications on Windows. How To Install Apache Spark On Windows 10: Step 1: Download winutils.exe Windows 10 operating system from git hub below link: After downloading the Wintulins file and create your own convenient. 7.
Please open an issue and feel free to contribute.. In Standalone and Mesos modes, this file can give machine specific information such as hostnames. Grab VSCode. PYSPARK_DRIVER_PYTHON or PYSPARK_PYTHON environment variable to detect SPARK_HOME safely. That's about the easiest way I've found. Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows).
It also returns TRUE if the environment was successfully set, and FALSE otherwise. Downloads are pre-packaged for a handful of popular Hadoop versions. Can someone help me with this? If spark is installed through binary download. set SPARK_HOME=%~dp0 .. Spark runs on Java 8, Python 2.7+/3.4+ and R 3.1+. Connect to your storage account. 2.
A System Properties dialog box appears. 3. The variable value points to your Java JDK location. export PYSPARK_SUBMIT_ARGS='--packages mysql:mysql-connector-java:5.1.49' spylon (scala) in Jupter Notebook. GIT Bash Command Prompt Windows 10; Download Binary Package Set your environment variable SPARK_HOME to root level directory where you installed Spark on your local machine. On the following Environment variable screen, add SPARK_HOME, HADOOP_HOME, JAVA_HOME by selecting the New option.
$ source ~/.bashrc. I put that file into Windows C Drive. Once complete, you will be able to run PySpark and GeoAnalytics Engine code in a python notebook, the PySpark shell, or with a python script. Apache Spark is a new and open-source framework used in the big data industry for real-time processing and batch processing. We need to issue this command from WSL: sudo apt-get install golang. 2. However, findspark is unable to recognize the SPARK_HOME variable, although os.environ on it works correctly. If you have placed spark code and winutils in a different directory, change file paths below.
Windows7 PS. In Windows standalone local cluster, you can use system environment variables to directly set these environment variables. C:\Users\Honey>pyspark The system cannot find the path specified. JAVA_HOME environment variable. Add this in system variable path --> Accept the license agreement and download the latest version of SPARK_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7 HADOOP_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7 PATH = %PATH%; C:\apps\spark-3.0.0-bin-hadoop2.7\bin Install winutils.exe on Windows Download winutils.exe file from winutils, and copy it to %SPARK_HOME%\bin folder. For the Scala API, Spark 2.3.4 uses Scala 2.11. In the New System Variable form, enter the name and value as follows: Click OK, and you will see the JAVA_HOME variable is added to the list. set SPARK_HOME=%~dp0 .. Posted By Jakub Nowacki, 11 August 2017. Important note: Always make sure to refresh the terminal environment; otherwise, the newly added environment variables will not be recognized. 3. export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7 export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export The following steps explain how to install Apache Spark and GeoAnalytics Engine on Windows or Linux using Spark in local standalone mode. Environment Variables. Paste the following cod. First, check your environment variables for Python and Spark. Click on Advanced System Settings and then the Environment Variables button.
Environment Variables. Rename log4j.properties.template to log4j.properties
Its easy to run locally on one machine all you need is to have java installed on your system PATH , or the JAVA_HOME environment variable pointing to a Java installation. This page summarizes the steps to install Spark 2.2.1 in your Windows environment.
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
spark-shell. os.environ in Python is a mapping object that represents the users environmental variables.
Next, run the following command: spark-shell.
First, we need to install Go on both platforms. Prerequisites: Java 8 or 11 (64-bit) Python 3.7+.
This module provides a portable way of using operating system dependent functionality. Check your IDE environment variable settings, your .bashrc , .zshrc , or .bash_profile file, and These helpers will assist you on the command line.
Make sure to replace
.NET Core 2.1, 2.2 and 3.1 are supported. Step 3: Open the environment variable on the laptop by typing it in the windows search bar. 4. The Environment Variables window is divided into two sections. You will be seeing spark-shell open up with an available spark context and session. Livy uses the Spark configuration under SPARK_HOME by default. Set DOTNET_WORKER_DIR and check dependencies. Open a Command Prompt window and type SETX /? Now visit the provided URL, and you are ready to interact with Spark via the Jupyter Notebook. Comparing with other computing technology, it provides implicit data parallelism and default fault tolerance. Setup environment variables. To avoid verbose INFO messages printed on the console, set rootCategory=WARN in the conf/ log4j.properties file. Select and edit this path variable and add below two lines to it. PYSPARK_DRIVER_PYTHON or PYSPARK_PYTHON environment variable to detect SPARK_HOME safely. I m working on Windows Os. Click through and complete the installation. To check everything is set up correctly, check that the JRE is available and the correct version: In a command window, run Java -version then spark-shell. Open System Environment Variables window and select Environment Variables. Add the following new USER variables: SPARK_HOME c:\spark; JAVA_HOME (the path you installed the JDK to in step 1, for example C:\ProgramFiles\Java\jdk1.8.0_101) Setting environment variables We have to setup below environment variables to let spark know where the required files are.
2. Here are mine: SPARK_HOME: C:\spark-1.6.0-bin-hadoop2.6\ I use Enthought Canopy, so Python is already integrated in my system path. appName ("SparkByExamples.com"). The master in the command can be an IP or hostname. C:\spark\bin. The defaults will add some useful directories to your path environment variable. Now you have completed the installation step, well create our first Spark project in Java.
It supports different languages, like Python, Scala, Java, and R. This opens up the New User Variables window where you can enter the variable name and value. @ashishambekar018 Could you please try the following steps:. Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows). Certain Spark settings can be configured through environment variables, which are read from the conf/spark-env.sh script in the directory where Spark is installed (or conf/spark-env.cmd on Windows). Since the hadoop folder is inside the SPARK_HOME folder, it is better to create HADOOP_HOME environment variable using a value of %SPARK_HOME%\hadoop. If I launch Spark from the command shell, it works as expected. Once environment box is open, go to Path variable for your user.
Now set the following environment variables.
However, if you prefer to use Scala, there is an option with spylon kernel. Install Scala to a suitable location on your machine (I use C:Scala for simplicity). The system cannot find the path specified. 1) Setup JAVA_HOME variable. python. I put that file into Windows C Drive. If the above command worked, you can now move on to accessing this storage account through Spark. 3. Save your file and use the source command to reload the bashrc file for your current shell session. spark.python.profile: false: Enable profiling in Python worker, the profile result will show up by sc.show_profiles(), or it will be displayed before the driver exiting. If you get an error, check what you get for 'spark_home'.
rem pip installed version of PySpark. Here are two screenshots: Make sure your have defined environment variables in Windows control panel->system->advanced system settings->environment variables: The PATH environment variable should be similar to: The following is one example: export PYSPARK_PYTHON=/path/to/your/python/executable 