Classification is the process of classifying the data with the help of class labels. For a data scientist, data mining can be a vague and daunting task it requires a diverse set of skills and knowledge of many data mining techniques to take raw data and successfully get insights from it. There is a huge amount of data in the shopping market, and the user needs to manage large data using different patterns. Answer (1 of 9): Classification is one of the most important tasks in data mining. Classification looks for new patterns, even if it means changing the way the data is organized. Classification is a data mining (machine learning) technique used to predict group membership for data instances. Types of Clustering. It includes collection, extraction, analysis, and statistics of data. 2/10/2021 Introduction to Data Mining, 2 nd Edition 13 Improving KNN Efficiency Avoid having to compute distance to all objects in the training set Multi-dimensional access methods (k-d trees) Fast approximate similarity search Locality Sensitive Hashing (LSH) Condensing Determine a smaller set of objects that give It uses 2. The book details the methods for data classification and introduces the concepts and methods for data clustering. 1. The mining model that an algorithm creates from your data can take various forms, including:A set of clusters that describe how the cases in a dataset are related.A decision tree that predicts an outcome, and describes how different criteria affect that outcome.A mathematical model that forecasts sales.More items
Random forest.
Open-pit mining is the activity of removing the earth to access the mineral deposits and continuing to do it vertically in an open-pit. Classification. Accuracy Accuracy of classifier refers to the ability of classifier. Find a model for class attribute as a function of the values of other attributes. The potential benefits of progress in classification are immense since the technique has a great impact on other areas, both within Data Mining and in its applications. The data is represented in the form of patterns and models are structured using classification and clustering techniques. and unsupervised learning. Chapter 4 Classification. Based on the number of classes present, there are two types of classification: Binary classification classify input objects into one of the two classes. 3. Classification is a predictive modeling approach for predicting the value of certain and constant target variables. Classification rule mining and association rule mining are two important data mining techniques. The machines learn from already labeled or classified data. Classification is a major technique in data mining and widely used in various fields.
Association. What is classification methods in data mining? The percentage of accuracy of every applied data mining classification technique is used as a standard for performance measure. Note Data can also be reduced by some other methods such as wavelet transformation, binning, histogram analysis, and clustering. Here we will discuss other classification methods such as Genetic Algorithms, Rough Set Approach, and Fuzzy Set Approach. This method is best suited for mineral deposits that are close to the surface of the earth but are not accumulated in a horizontal manner. I. 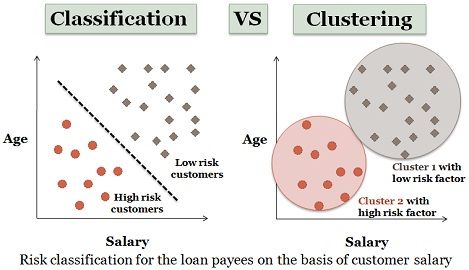 MBR is an empirical classification method and operates by comparing new unclassified records with known examples and patterns. For instance, a supermarket could determine that customers often purchase whipped cream when they buy strawberries and vice versa. There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. Note Data can also be reduced by some other methods such as wavelet transformation, binning, histogram analysis, and clustering. Typical Associative Classification Methods. Logistic Regression. Model selection. Classification techniques in Data Mining Let us see the different tutorials related to the classification in Data Mining. How to Access Classification Methods in Excel. In the toolbar, click XLMINER PLATFORM. #4) Decision Tree Induction. Anomaly detection, Association rule learning, Clustering, Classification, Regression, Summarization. Comparison of Classification and Prediction Methods. GIST OF DATA MINING : Choosing the correct classification method, like decision trees, Bayesian networks, or neural networks. Classification predicts the categorical labels of data with the prediction models. 04 Classification in Data Mining. It predict the class label correctly and the accuracy Classification predictive modeling is the task of approximating a mapping function (f) from input variables (X) to discrete output variables (y). Clustering is very similar to classification, but involves grouping chunks of data together based on their similarities. 1.1 Structured Data Classification. These two forms are as follows: Classification models predict categorical class labels; and prediction models predict continuous valued functions. Classification looks for new patterns, even if it means changing the way the data is organized. It offers several data mining methods like exploratory data analysis, statistical learning and machine learning. Here we will discuss other classification methods such as Genetic Algorithms, Rough Set Approach, and Fuzzy Set Approach. #3) Classification. #3) Classification. MBR is an empirical classification method and operates by comparing new unclassified records with known examples and patterns. 1. Applications of classification arise in diverse fields, such as retail target marketing, customer retention, fraud detection, and medical diagnosis. Classification rule mining aims to discover a small set of rules in the database to form an accurate classifier. Shopping Market Analysis. 1. 1. Classes are sometimes called as targets/ labels or categories. Classification is a major technique in data mining and widely used in various fields. Answer - Click Here: 3. Introduction to Classification Algorithms. Open-pit mining. These two forms are as follows: Classification models predict categorical class labels; and prediction models predict continuous valued functions. 3. 5. Clustering is the result of unsupervised learning where The main purpose of data mining is to extract valuable information from available data. What does the robustness of a data mining method refer to. Frequent Pattern Mining (AKA Association Rule Mining) is an analytical process that finds frequent patterns, associations, or causal structures from data sets found in various kinds of data repositories. It then presents information about data warehouses, online analytical processing (OLAP), and data cube technology. List Of Data Extraction Techniques. An essential process used for applying intelligent methods to extract the data patterns is named as . 1 Introduction to Classification Methods. #5) Bayes Classification. It may be defined as the process of assigning predefined class labels to instances based on their features or attributes. There are many ways to group clustering methods into categories. Classifiers in Machine Learning. Learn Decision tree induction on categorical attributes. It can be used to predict categorical class labels and classifies data based on training set and class labels and it can be used for classifying newly available data.The term could cover any context in which some decision or forecast is made on the basis of presently Classification is a technique where we categorize data into a given number of classes.
MBR is an empirical classification method and operates by comparing new unclassified records with known examples and patterns. For instance, a supermarket could determine that customers often purchase whipped cream when they buy strawberries and vice versa. There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. Note Data can also be reduced by some other methods such as wavelet transformation, binning, histogram analysis, and clustering. Typical Associative Classification Methods. Logistic Regression. Model selection. Classification techniques in Data Mining Let us see the different tutorials related to the classification in Data Mining. How to Access Classification Methods in Excel. In the toolbar, click XLMINER PLATFORM. #4) Decision Tree Induction. Anomaly detection, Association rule learning, Clustering, Classification, Regression, Summarization. Comparison of Classification and Prediction Methods. GIST OF DATA MINING : Choosing the correct classification method, like decision trees, Bayesian networks, or neural networks. Classification predicts the categorical labels of data with the prediction models. 04 Classification in Data Mining. It predict the class label correctly and the accuracy Classification predictive modeling is the task of approximating a mapping function (f) from input variables (X) to discrete output variables (y). Clustering is very similar to classification, but involves grouping chunks of data together based on their similarities. 1.1 Structured Data Classification. These two forms are as follows: Classification models predict categorical class labels; and prediction models predict continuous valued functions. Classification looks for new patterns, even if it means changing the way the data is organized. It offers several data mining methods like exploratory data analysis, statistical learning and machine learning. Here we will discuss other classification methods such as Genetic Algorithms, Rough Set Approach, and Fuzzy Set Approach. #3) Classification. #3) Classification. MBR is an empirical classification method and operates by comparing new unclassified records with known examples and patterns. 1. Applications of classification arise in diverse fields, such as retail target marketing, customer retention, fraud detection, and medical diagnosis. Classification rule mining aims to discover a small set of rules in the database to form an accurate classifier. Shopping Market Analysis. 1. 1. Classes are sometimes called as targets/ labels or categories. Classification is a major technique in data mining and widely used in various fields. Answer - Click Here: 3. Introduction to Classification Algorithms. Open-pit mining. These two forms are as follows: Classification models predict categorical class labels; and prediction models predict continuous valued functions. 3. 5. Clustering is the result of unsupervised learning where The main purpose of data mining is to extract valuable information from available data. What does the robustness of a data mining method refer to. Frequent Pattern Mining (AKA Association Rule Mining) is an analytical process that finds frequent patterns, associations, or causal structures from data sets found in various kinds of data repositories. It then presents information about data warehouses, online analytical processing (OLAP), and data cube technology. List Of Data Extraction Techniques. An essential process used for applying intelligent methods to extract the data patterns is named as . 1 Introduction to Classification Methods. #5) Bayes Classification. It may be defined as the process of assigning predefined class labels to instances based on their features or attributes. There are many ways to group clustering methods into categories. Classifiers in Machine Learning. Learn Decision tree induction on categorical attributes. It can be used to predict categorical class labels and classifies data based on training set and class labels and it can be used for classifying newly available data.The term could cover any context in which some decision or forecast is made on the basis of presently Classification is a technique where we categorize data into a given number of classes.  Classification and regression are the properties of. #7) Outlier Detection. These methods include k-nearest neighbor classification, case-based reasoning, genetic algorithms, rough set,snd fuzzy set approaches. Procedure. Market basket analysis is a modelling technique is used to do the analysis. It models a prediction 3. It is often viewed as forecasting a continuous value, while classification forecasts a discrete value. 1. Classification is a supervised data mining technique that involves assigning a label to a set of unlabeled input objects. 1. Regression. List Of Data Extraction Techniques. Classification and Predication in Data Mining. 8. Classification analysis.
Classification and regression are the properties of. #7) Outlier Detection. These methods include k-nearest neighbor classification, case-based reasoning, genetic algorithms, rough set,snd fuzzy set approaches. Procedure. Market basket analysis is a modelling technique is used to do the analysis. It models a prediction 3. It is often viewed as forecasting a continuous value, while classification forecasts a discrete value. 1. Classification is a supervised data mining technique that involves assigning a label to a set of unlabeled input objects. 1. Regression. List Of Data Extraction Techniques. Classification and Predication in Data Mining. 8. Classification analysis.
Open-pit mining often impacts a narrower surface area.
Data Mining Wizard. The most popular classification algorithms in data mining are the K-Nearest Neighbor and decision tree algorithms.  Sequential patterns or Pattern tracking. 2/10/2021 Introduction to Data Mining, 2 nd Edition 13 Improving KNN Efficiency Avoid having to compute distance to all objects in the training set Multi-dimensional access methods (k-d trees) Fast approximate similarity search Locality Sensitive Hashing (LSH) Condensing Determine a smaller set of objects that give Classification is Introduction to Classification Algorithms. Classification predicts the categorical labels of data with the prediction models. Classification is the processing of finding a set of models (or functions) which describe and distinguish data classes or concepts. Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 # Rule-Based Classifier Classify records by using a collection of ifthen rules Rule: ( Condition ) y where Condition is a conjunctions of attributes y is the class label LHS : rule antecedent or condition RHS : Data-mining: Classification. 1. Decision trees can be constructed relatively quickly, compared to other methods. https://www.geeksforgeeks.org/basic-concept-classification-data-mining Need a sample of data, where all class values are known. Purpose Of Data Mining Techniques. In recent data mining projects, various major data mining techniques have been developed and used, including association, classification, clustering, prediction, sequential patterns, and regression. Data-mining: Classification.
Sequential patterns or Pattern tracking. 2/10/2021 Introduction to Data Mining, 2 nd Edition 13 Improving KNN Efficiency Avoid having to compute distance to all objects in the training set Multi-dimensional access methods (k-d trees) Fast approximate similarity search Locality Sensitive Hashing (LSH) Condensing Determine a smaller set of objects that give Classification is Introduction to Classification Algorithms. Classification predicts the categorical labels of data with the prediction models. Classification is the processing of finding a set of models (or functions) which describe and distinguish data classes or concepts. Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 # Rule-Based Classifier Classify records by using a collection of ifthen rules Rule: ( Condition ) y where Condition is a conjunctions of attributes y is the class label LHS : rule antecedent or condition RHS : Data-mining: Classification. 1. Decision trees can be constructed relatively quickly, compared to other methods. https://www.geeksforgeeks.org/basic-concept-classification-data-mining Need a sample of data, where all class values are known. Purpose Of Data Mining Techniques. In recent data mining projects, various major data mining techniques have been developed and used, including association, classification, clustering, prediction, sequential patterns, and regression. Data-mining: Classification.
It solves new problems based on the solutions of similar past problems. Classification is a supervised data mining technique that involves assigning a label to a set of unlabeled input objects. Classification is the process of predicting the class of given data points. chapter emphasizes that classification and regression trees are useful for extracting structure from large multivariate data sets. Decision trees can be constructed relatively quickly, compared to other methods. In recent data mining projects, various major data mining techniques have been developed and used, including association, classification, clustering, prediction, sequential patterns, and regression. Data mining is considered an interdisciplinary field that joins the techniques of computer science and statistics.
Data mining involves six common classes of tasks.  #2) Correlation Analysis. On the other hand, Clustering is similar to classification but there are no predefined class labels. In the ribbon's Data Mining section, click Classify. An algorithm in data mining (or machine learning) is a set of heuristics and calculations that creates a model from data. Learn Attribute selection Measures. Based on the number of classes present, there are two types of classification: Binary classification classify input objects into one of the two classes. Classification techniques in data mining are capable of processing a large amount of data. Chapter 4 Classification. Here are the articles related to classification in data mining: * Classification In Data Mining. Classification and Predication in Data Mining. Launch Excel. Data mining in education is the field that allows us to make predictions about the future by examining the data obtained so far in the field of education by using machine learning techniques. There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. This initial population consists of randomly generated rules. INTRODUCTION There are many different methods used to perform the data mining task. Among these models, decision trees are particularly suited for data mining. #1) Frequent Pattern Mining/Association Analysis. Prediction. To improve the business opportunity and the quality of service provided efficient data mining must be implemented, and good understanding of the data mining techniques is required for that. Linear Regression. As a supervised data mining method, classification begins with the method described above. The constructed model, which is based on training set is represented as classification rules, decision trees or mathematical formulae. Data mining is the process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. It is used to classify different data in different classes. In fact, several classification algorithms; including SimpleLogistic, Instance-based k-nearest Neighbors (IBK), Naive Bayes, Stochastic Gradient #5) Bayes Classification. Method Learning Strategy Data Mining: Manually analyze a given dataset to gain insights and predict potential outcomes. Comparison of Classification and Prediction Methods. In estimating the accuracy of data mining (or other) classification models, the true positive rate is the ratio of correctly classified positives divided by the total positive count. October 8, 2015 Data Mining: Concepts and Techniques 5 ClassificationA Two-Step Process Model construction: describing a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction is training set The model is represented as classification rules, decision The main goal of a classification problem is to identify the category/class to which a new data will fall under. o Build classifier: Organize rules according to decreasing precedence based on confidence and then support. The wizard is quick and easy, and guides you through the process of creating a data mining structure and an initial related mining model, and includes the tasks of selecting an algorithm type and a data source, and defining the case data used for analysis. This study compares four free and open source Data Mining tools: KNIME, Orange, RapidMiner and Weka. Decision Trees. focused on the application of various data mining classification techniques using different machine learning tools such as WEKA and Rapid miner over the public healthcare dataset for analyzing the health care system.
#2) Correlation Analysis. On the other hand, Clustering is similar to classification but there are no predefined class labels. In the ribbon's Data Mining section, click Classify. An algorithm in data mining (or machine learning) is a set of heuristics and calculations that creates a model from data. Learn Attribute selection Measures. Based on the number of classes present, there are two types of classification: Binary classification classify input objects into one of the two classes. Classification techniques in data mining are capable of processing a large amount of data. Chapter 4 Classification. Here are the articles related to classification in data mining: * Classification In Data Mining. Classification and Predication in Data Mining. Launch Excel. Data mining in education is the field that allows us to make predictions about the future by examining the data obtained so far in the field of education by using machine learning techniques. There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. This initial population consists of randomly generated rules. INTRODUCTION There are many different methods used to perform the data mining task. Among these models, decision trees are particularly suited for data mining. #1) Frequent Pattern Mining/Association Analysis. Prediction. To improve the business opportunity and the quality of service provided efficient data mining must be implemented, and good understanding of the data mining techniques is required for that. Linear Regression. As a supervised data mining method, classification begins with the method described above. The constructed model, which is based on training set is represented as classification rules, decision trees or mathematical formulae. Data mining is the process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. It is used to classify different data in different classes. In fact, several classification algorithms; including SimpleLogistic, Instance-based k-nearest Neighbors (IBK), Naive Bayes, Stochastic Gradient #5) Bayes Classification. Method Learning Strategy Data Mining: Manually analyze a given dataset to gain insights and predict potential outcomes. Comparison of Classification and Prediction Methods. In estimating the accuracy of data mining (or other) classification models, the true positive rate is the ratio of correctly classified positives divided by the total positive count. October 8, 2015 Data Mining: Concepts and Techniques 5 ClassificationA Two-Step Process Model construction: describing a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction is training set The model is represented as classification rules, decision The main goal of a classification problem is to identify the category/class to which a new data will fall under. o Build classifier: Organize rules according to decreasing precedence based on confidence and then support. The wizard is quick and easy, and guides you through the process of creating a data mining structure and an initial related mining model, and includes the tasks of selecting an algorithm type and a data source, and defining the case data used for analysis. This study compares four free and open source Data Mining tools: KNIME, Orange, RapidMiner and Weka. Decision Trees. focused on the application of various data mining classification techniques using different machine learning tools such as WEKA and Rapid miner over the public healthcare dataset for analyzing the health care system.
Model construction. 1.1 Classification. Read: Data Mining vs Machine Learning Linear Regression. KeywordsData Mining, Classification, Decision tree induction,Neural networks. Data Mining: Concepts and Techniques 4 ClassificationA Two-Step Process Model construction: describing a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction: training set The model is represented as classification rules, decision trees, A predefine class label is assigned to every sample tuple or object. Classification can be performed on structured or unstructured data. Data mining involves six common classes of tasks. Classification: This technique is used to obtain important and relevant information about data and metadata. The speed, scalability and robustness are considerable factors in classification and prediction methods. We will cover all types of Algorithms in Data Mining: Statistical Procedure Based Approach, Machine Learning-Based Approach, Neural Network, Classification Algorithms in Data Mining, ID3 Algorithm, C4.5 Algorithm, K Nearest Neighbors Algorithm, Nave Bayes Algorithm, The goal of classification is to accurately predict the target class for each case in the data. Different Data Mining Methods. Data mining is the process of applying these methods to data with the intention of uncovering hidden patterns.[2,3,13]. #1) Frequent Pattern Mining/Association Analysis. The percentage of accuracy of every applied data mining classification technique is used as a standard for performance measure. Model usage 8. Data Mining Techniques Many important data mining techniques have been developed and applied in data mining projects, particularly classification, association, clustering, prediction, sequential models, and decision trees. Genetic Algorithms The idea of genetic algorithm is derived from natural evolution. It is used to find a correlation between two or more items by identifying the hidden pattern in the data set and hence also called 2.
the process of creating knowledge from a set of data, such as images or a database. Many practical decision-making tasks can be formulated as classification problems. All these tasks are either predictive data mining tasks or descriptive data mining tasks. Here is the criteria for comparing the methods of Classification and Prediction . Some scientists, such as Harper and Jonas, have crafted more narrow definitions that focus solely on the predictive nature of data mining. 2. Free and open source Data Mining software tools are available from the Internet that offers the capability of performing classification through different techniques. Data classification is one of the effective and XLMiner supports all facets of the data mining process, including customers who are likely to buy or not buy a particular product in a supermarket.
Classification techniques in Data Mining Let us see the different tutorials related to the classification in Data Mining. It provides the tools necessary for data mining. 2. Decision Trees. Decision trees. Other Classification Methods Data Mining 1 Instance-Based Learning (kNN) Artificial Neural Networks Classifiers in Machine Learning 1. Following are the various real-life examples of data mining, 1. decision trees, neural networks, etc). 2.
Data mining is the process of discovering predictive information from the analysis of large databases. The data sources can include databases, data warehouses, the web, and other information repositories or data that are streamed into the system dynamically. The list of data mining algorithms for classification include decision trees, logistic regression, support vector machine and more. The initial data for other tasks will be different. One must not mix classification with clustering. 5. The book details the methods for data classification and introduces the concepts and methods for data clustering.
Association. This article on classification algorithms gives an overview of different methods commonly used in data mining techniques with different principles. The main goal of a classification problem is to identify the category/class to which a new data will fall under. Further Discussion on Regression and Classification Trees, Computer Software, and Other Useful Classification Methods. Association makes a correlation between two or more items to identify a pattern. The derived model is based on the analysis of a set The most popular classification algorithms in data mining are the K-Nearest Neighbor and decision tree algorithms. 1. The Key Differences Between Classification and Clustering are: Classification is the process of classifying the data with the help of class labels. The third stage, prediction, is used to predict the response variable value based on a predictor variable. This application of data mining in healthcare involves establishing normal patterns, then identifying unusual patterns of medical claims by clinics, physicians, labs, or others. In this paper, we present the basic classification techniques. When we apply cluster analysis to a dataset, we let the values of the variables that were measured tell us if there is any structure to the observations in the data set, by choosing a suitable metric and seeing if groups of observations that are all close together can be found. Building Classification Rules ODirect Method: Extract rules directly from data e.g. In other words, it finds the outliers. Classification can be performed on structured or unstructured data. 2. This article on classification algorithms gives an overview of different methods commonly used in data mining techniques with different principles. Data Mining Techniques Many important data mining techniques have been developed and applied in data mining projects, particularly classification, association, clustering, prediction, sequential models, and decision trees. Data mining is the emerging field which attracted many industries to manage such amount of data. When we apply cluster analysis to a dataset, we let the values of the variables that were measured tell us if there is any structure to the observations in the data set, by choosing a suitable metric and seeing if groups of observations that are all close together can be found. 5. Types of Data Mining TechniquesClassification. This data analysis is implemented to regain vital and actual information. Clustering. Cluster analysis is a bit different classifying in the sense that here the pieces are grouped according to their similarities.Regression. Association. More items